This project aims to model review-response pairs in the
hospitality domain and apply the retrieve-edit-rerank framework
proposed in paper
Simple and Effective Retrieve-Edit-Rerank Text Generation
to improve model performance. Compared to the classic Seq2Seq
framework, this method is intended to utilize potentially
suitable responses from a corpus containing artificial
responses.
Data
The data experimented on is the corpus of review-response pairs
from TripAdvisor. Some pre-processing operations were applied
before dataset splitting to avoid responses with misleading
information.
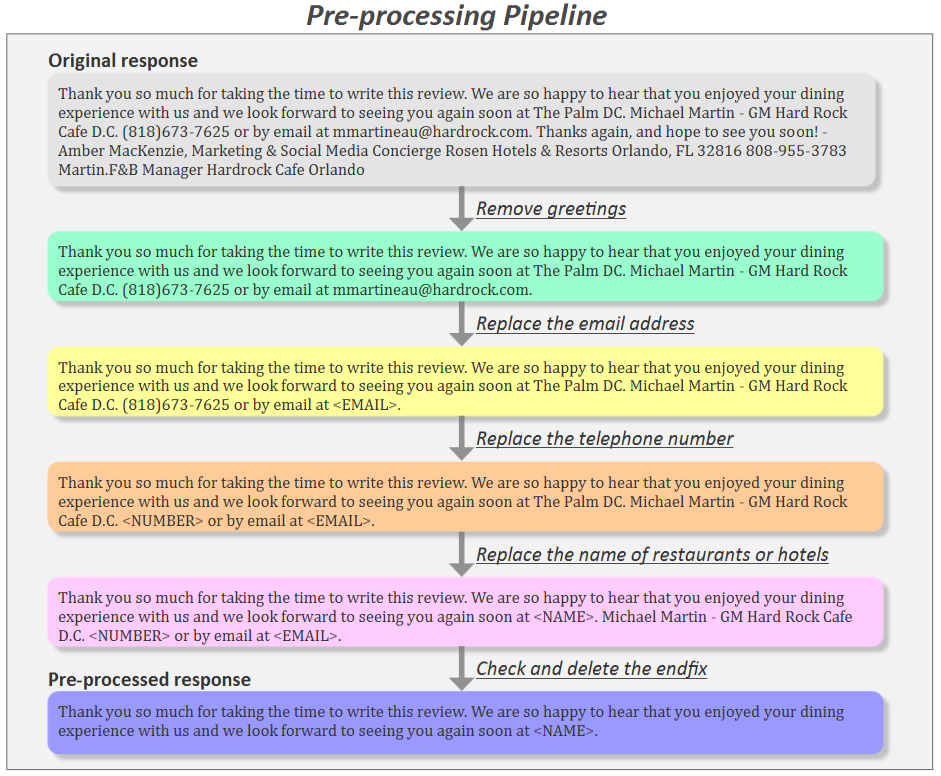
Applying the preprocessing pipeline to raw data and using
cleaned data for later steps can help improve model performance
and generate more meaningful responses.
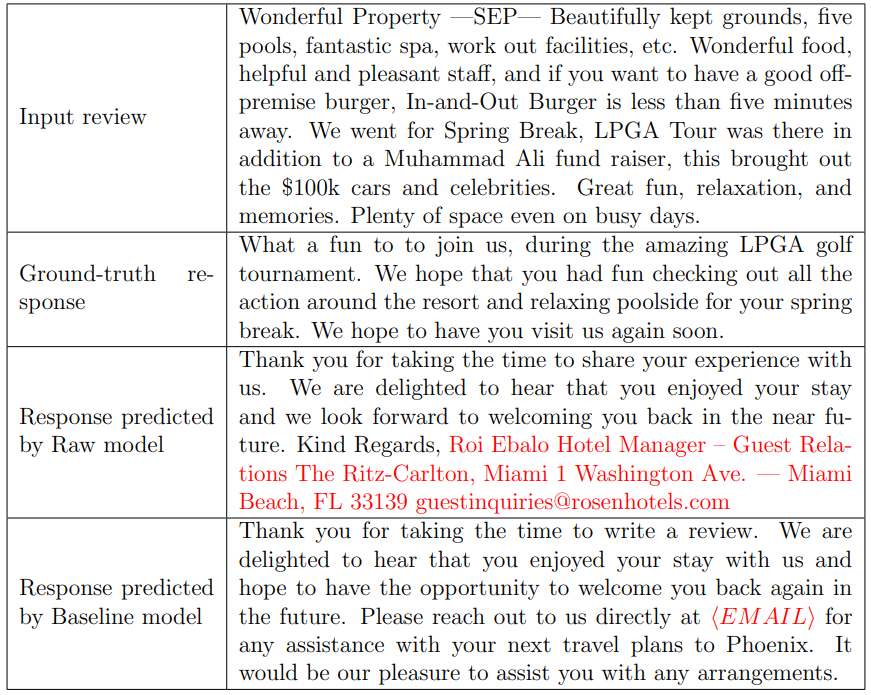
Example Analysis
The HNSW retrieval method was used to get the most similar
responses given a user-written hospitality review as input. The
retrieved responses were regarded as soft templates and were
concatenated with the original review as augmented inputs for
the transformer-based model. With several automatic evaluation
metrics, we confirmed that soft templates could help to generate
more specific responses, and the post-gen ranking technique
could improve model performance.

